The past weeks, our intern Lieselot, has been researching ways to deploy containers on Google Cloud Platform. She has written this blogpost about the three most recent & common ways to deploy containers on GCP. Enjoy!
With the addition of Cloud Run Job to Google Cloud serverless stack, there is yet another way to deploy containers. The diversity developers have today when they need to deploy containers in the cloud is enormous. In this blogpost I will try to give you a brief overview of the most recent options and their common use cases focussed on the Google Cloud Platform.
Cloud Run jobs
Next to Cloud Run Services Google released Cloud Run Jobs. While Cloud Run Services focus on serving HTTP requests, Jobs focus on the exact opposite and can only be triggered with a scheduler or started manually. Therefore it’s most suitable for batch processes, database migrations, scripts on servers and so on. All tasks that can run unattended and in parallel make a great fit for this one.
To create a Cloud Run Job on GCP you need to give a name and image_URL as reference to a container image. All other parameters are optional or can be added later if preferred. Another important parameter is the amount of tasks the job should execute. Each task will have its own container and should be independent. Multiple tasks can run in parallel but only if your code splits the data between workers if needed. As for resources that may not be able to handle a great amount of requests when executing a job (such as a database accepting only a limited amount of connections), you can scale back the amount of tasks running in parallel.
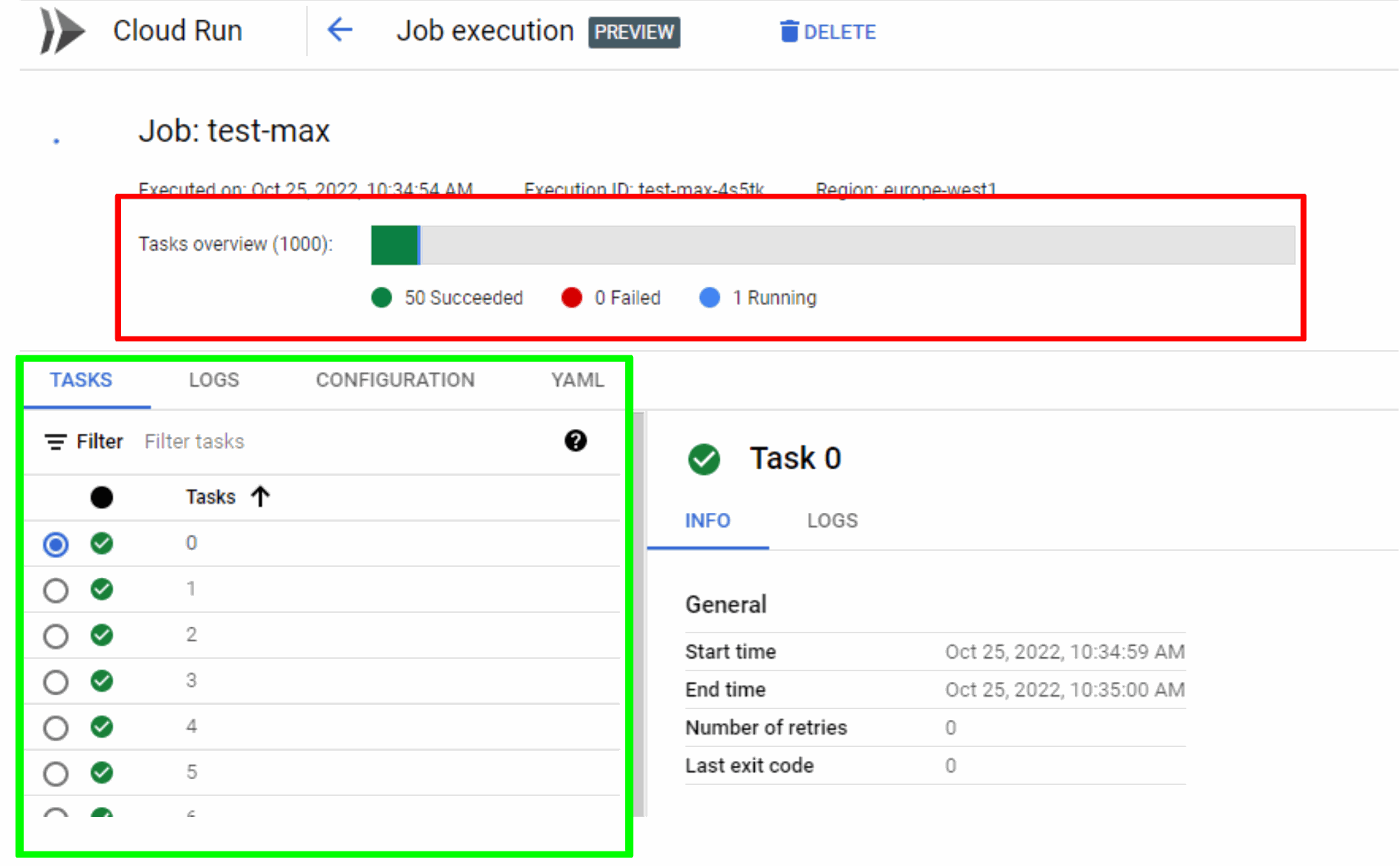
If the job should be executed immediately you can add –execute now or start the job manual when creation is finished. GCP also provides the option to schedule the Cloud Run Job with Cloud Scheduler, Google’s cloud version for cron jobs. While a job is running you can see how many tasks are running, successful or failed. As well as an overview of all the tasks with their logs and configuration, details below. Currently the only way to stop a Job before it’s finished, is to delete it.
- In the red rectangle you have the overview of how many tasks have finished successful, failed or are still running.
- In the green rectangle you’ll see the overview of the job, starting with the different tasks - the general logs - configuration and YAML-config file
- For each task in the job you can see info and logs of that specific task right of the green rectangle
When a Job is executed the logs are written to Cloud Logging and monitoring data is sent to Cloud Monitoring, so even if a Job is deleted logs stay available. In addition to the general logging you can also find the logs of the most recent 10 000 executions in the execution details pane along with any execution in the last 7 days.
How does Cloud Run Jobs fit in a blogpost on how to deploy containers? Well where Google Cloud Run Services and Google Kubernetes Engine still require some management, the containers that Cloud Run Jobs uses startup way faster and delete themselves immediately when finished so you don’t have to put any effort in managing that either.
Cloud Run Services
With Cloud Run, Google gives the flexibility and speed of a serverless architecture without losing the computing power containerized solution can offer. Cloud Run is a fully-managed compute environment for deploying serverless HTTP containers. It is designed to listen for and serve requests.
Cloud Run Services lets you deploy containers written in the language of your choice, you can define how Google scales those containers. By default Cloud Run will scale to zero if there are no triggers for 15 minutes, depending on your needs you can define how many instances have to be available all the time or how long a request can stay out before the instance can shutdown.
We already briefly discussed the difference between Cloud Run Jobs and Cloud Run Services. Biggest difference is that Cloud Run Services is able to handle HTTP(S) requests, opening up a great deal of possibilities to trigger Cloud Run:
- using gRPC: As google recommends configuring your service to use HTTP/2 this can be placed under HTTP-triggers for Cloud Run. Most given use case: simple, high performance communication between internal microservices.
- using WebSockets: Keep in mind Cloud Run containers have built-in load balancing so your WebSockets requests may end up in a different container. Make sure your data is synchronized between container instances if you want to use WebSockets as a trigger.
- Trigger from Pub/Sub: Securly process messages pushed from a Pub/Sub subscription. Possible use case: publish and process own custom events. Make sure to set the right acknowledgement deadline for the setup to work.
- Cloud Tasks: Asynchronous processing of tasks. Typically used to delay background tasks to ensure the application runs fast and smooth, even when traffic spikes. Also used to limit call rate to backing services.
- Eventarc: Cloud Run services can receive notifications of a specified event or set of events. Event type triggers that can be used are audit logs that are created, direct events and messages published to Pub/Sub.
Kubernetes Engine
Google Kubernetes Engine (GKE) is a managed Kubernetes platform and is the best option for the orchestration of containers. Not only do you have full control over your containers but also over the environment. Going from networking to storage, here you have complete control how they will behave.With GKE Google offers running your application in clusters while profiting off their experience in running production workloads in containers. The key features being:
- Auto-scaling of cluster and pod: 4-way auto-scaling - horizontal and vertical pod, cluster on a per-node-per-pool basis and automatically adjust memory and CPU.
- Hybrid networking: The possibility to reserve an IP addresses for the cluster that are able to coexist through the Cloud VPN
- GKE sandbox: Additional defense layer between workloads to improve the security of containerized workloads.
- Auto repair and Auto upgrade: If a node health check fails GKE will begin that node’s repair process. GKE will also keep your cluster up-to-date with every latest Kubernetes version release.
This mainly means you have the benefits of the 2 platforms in 1 product. Depending on the amount of responsibility, control and flexibility you need, you choose from 2 modes of operation:
- autopilot: GKE gives you an optimized cluster with hands-off experience because it provisions and manages its underlying infrastructure.
- standard: You have node configuration possibilities by managing the underlying infrastructure of your cluster.
How do all the options relate to each other?
Now that we have discussed the most common used options it’s time to compare them. Once again, this blog is not supposed to push you in one direction but is supposed to help you pick the right service to deploy your containers.
Feature | Cloud Run Services | Cloud Run Jobs | GKE |
Required knowhow* | 5 | 3 | 8 |
Startup time | Maximum within 4 minutes of the request to start container - normally a couple a seconds | Couple of seconds per container | Depending on the size of the cluster. |
Updates within your containers | you should update them yourself | you should update them yourself | provides automated upgrades, repair of faulty notes |
Use cases | serverless platform for stateless containerized http-microservices | unattended jobs, batch jobs, administrative jobs, … | full-featured container orchestration |
*on a scale from 1-10 where 1 is the least and 10 the most.
Sources
- https://blog.kornelondigital.com/2021/10/27/scheduling-tasks-on-the-google-cloud-platform-gcp
- https://www.sphereinc.com/blogs/when-to-choose-app-engine-vs-cloud-functions-or-cloud-run-in-gcp
- https://cloud.netapp.com/blog/gcp-cvo-blg-google-cloud-containers-top-3-options-for-containers-on-gcp
- https://cloud.google.com/run/docs/container-contract
- https://cloud.google.com/kubernetes-engine/docs/concepts/autopilot-overview
- https://cloud.google.com/kubernetes-engine/docs/concepts/kubernetes-engine-overview
- https://cloud.google.com/blog/topics/developers-practitioners/cloud-run-story-serverless-containers/
- https://www.cloudmatos.com/blog/the-benefits-of-google-kubernetes-engine